Deep neural networks have amply demonstrated their prowess but estimating the reliability of their predictions remains challenging. Deep Ensembles are widely considered as being one of the best methods for generating uncertainty estimates but are very expensive to train and evaluate. MC-Dropout is another popular alternative, which is less expensive, but also less reliable. Our central intuition is that there is a continuous spectrum of ensemble-like models of which MC-Dropout and Deep Ensembles are extreme examples. The first uses an effectively infinite number of highly correlated models while the second relies on a finite number of independent models.
To combine the benefits of both, we introduce Masksembles. Instead of randomly dropping parts of the network as in MC-dropout, Masksembles relies on a fixed number of binary masks, which are parameterized in a way that allows to change correlations between individual models. Namely, by controlling the overlap between the masks and their density one can choose the optimal configuration for the task at hand. This leads to a simple and easy to implement method with performance on par with Ensembles at a fraction of the cost. We experimentally validate Masksembles on two widely used datasets, CIFAR10 and ImageNet

Controllable correlation of Masksembles submodels
creates trade-off between quality of generated uncertainty, accuracy and model's computational overheads.
Tuning these parameters leads to optimal configurations that allow for the fulfillment of computational
and performance constraints for each particular task.
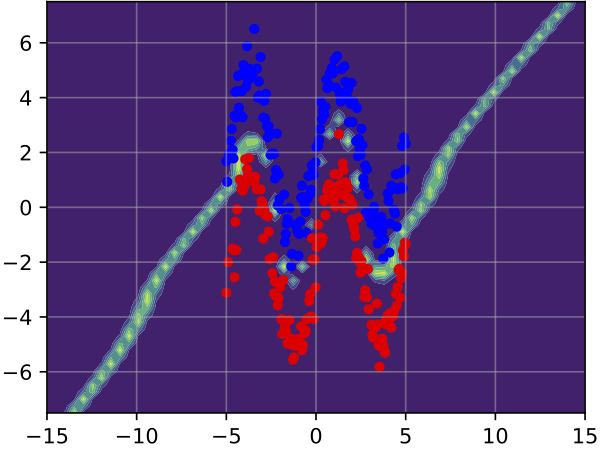
Single Model
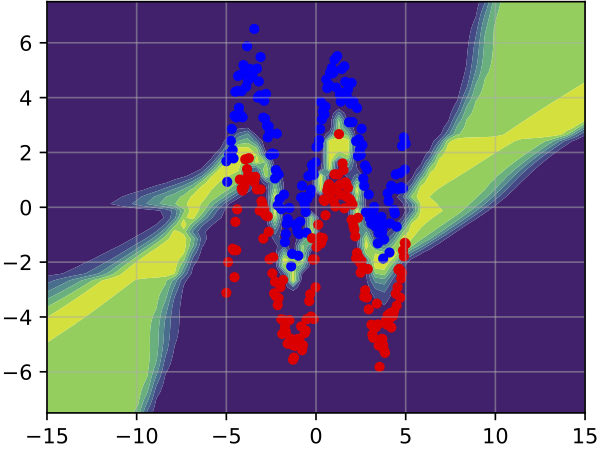
Deep Ensembles
@inproceedings{Durasov21,
author = {N. Durasov and T. Bagautdinov and P. Baque and P. Fua},
title = {{Masksembles for Uncertainty Estimation}},
booktitle = CVPR,
year = 2021
}