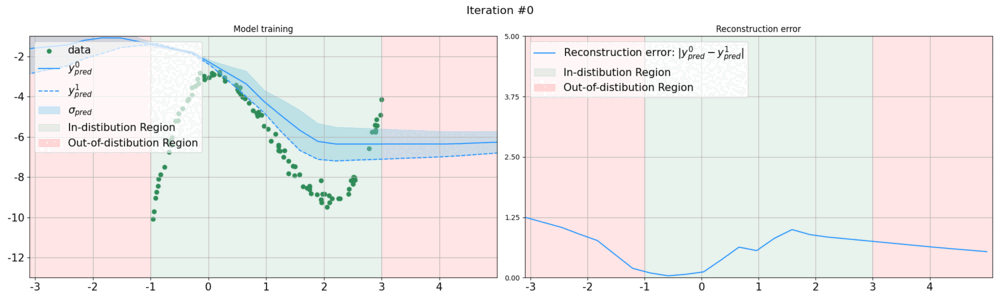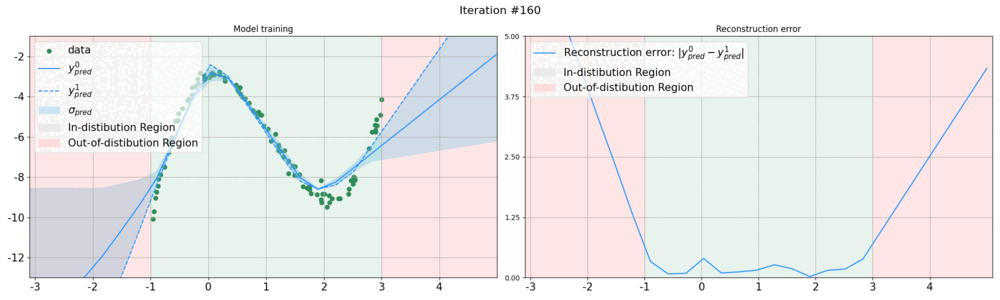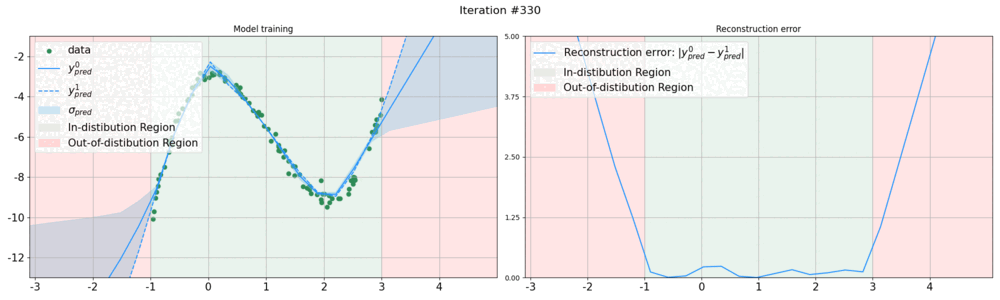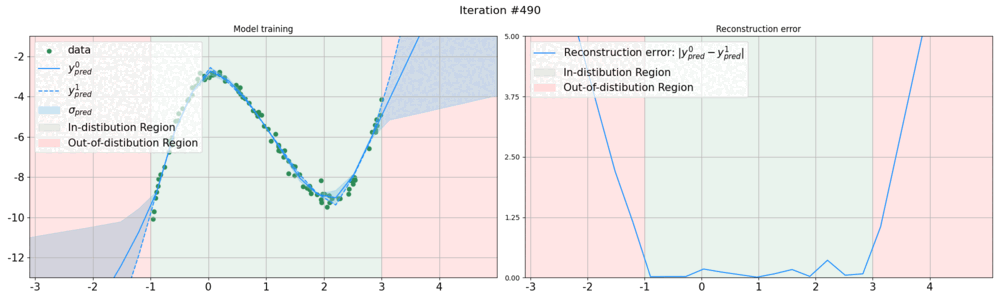
Whereas the ability of deep networks to produce useful predictions on many kinds of data has been amply demonstrated, estimating the reliability of these predictions remains challenging. Sampling approaches such as MC-Dropout and Deep Ensembles have emerged as the most popular ones for this purpose. Unfortunately, they require many forward passes at inference time, which slows them down. Sampling-free approaches can be faster but often suffer from other drawbacks, such as lower reliability of uncertainty estimates, difficulty of use, and limited applicability to different types of tasks and data.
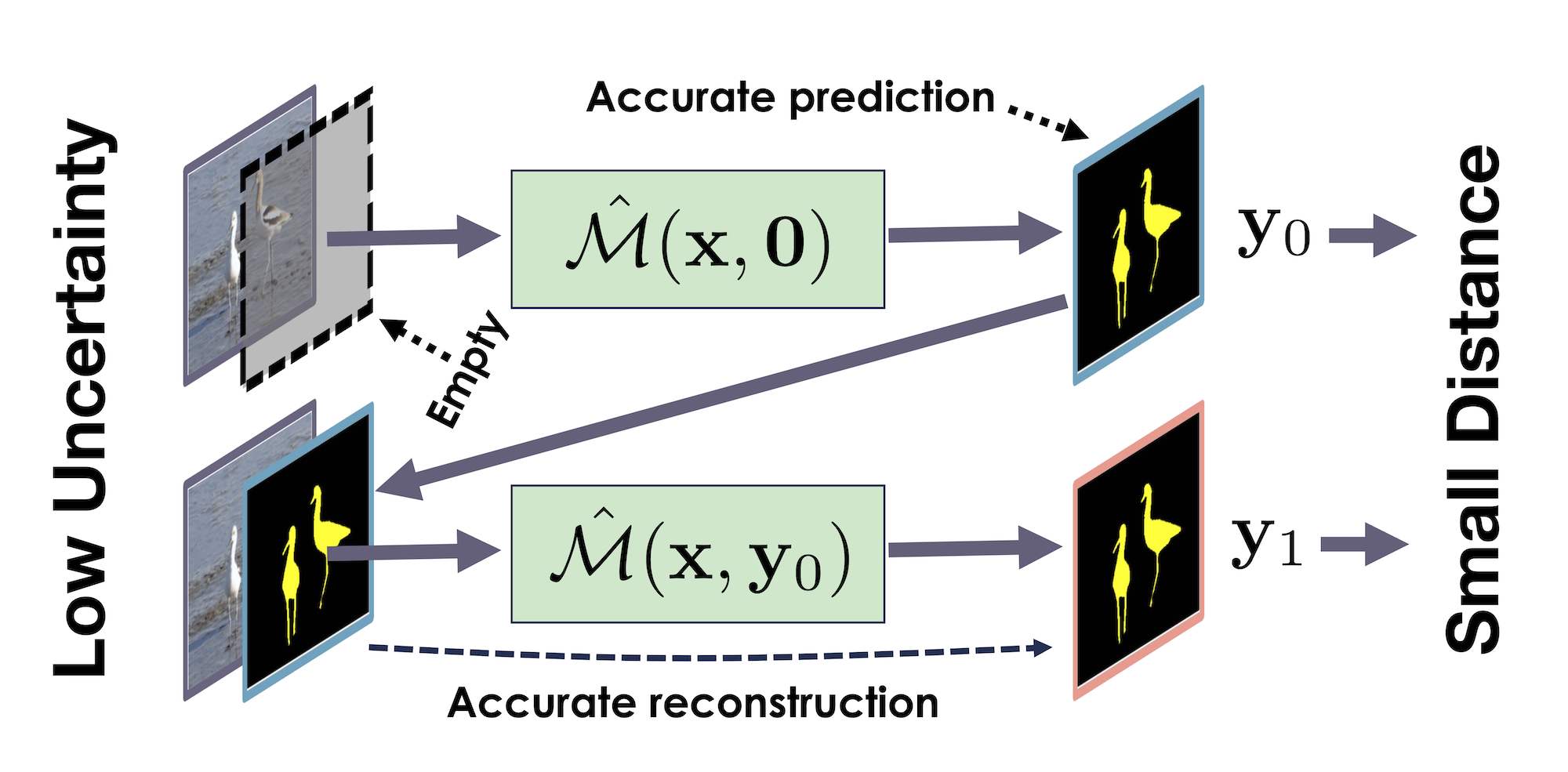
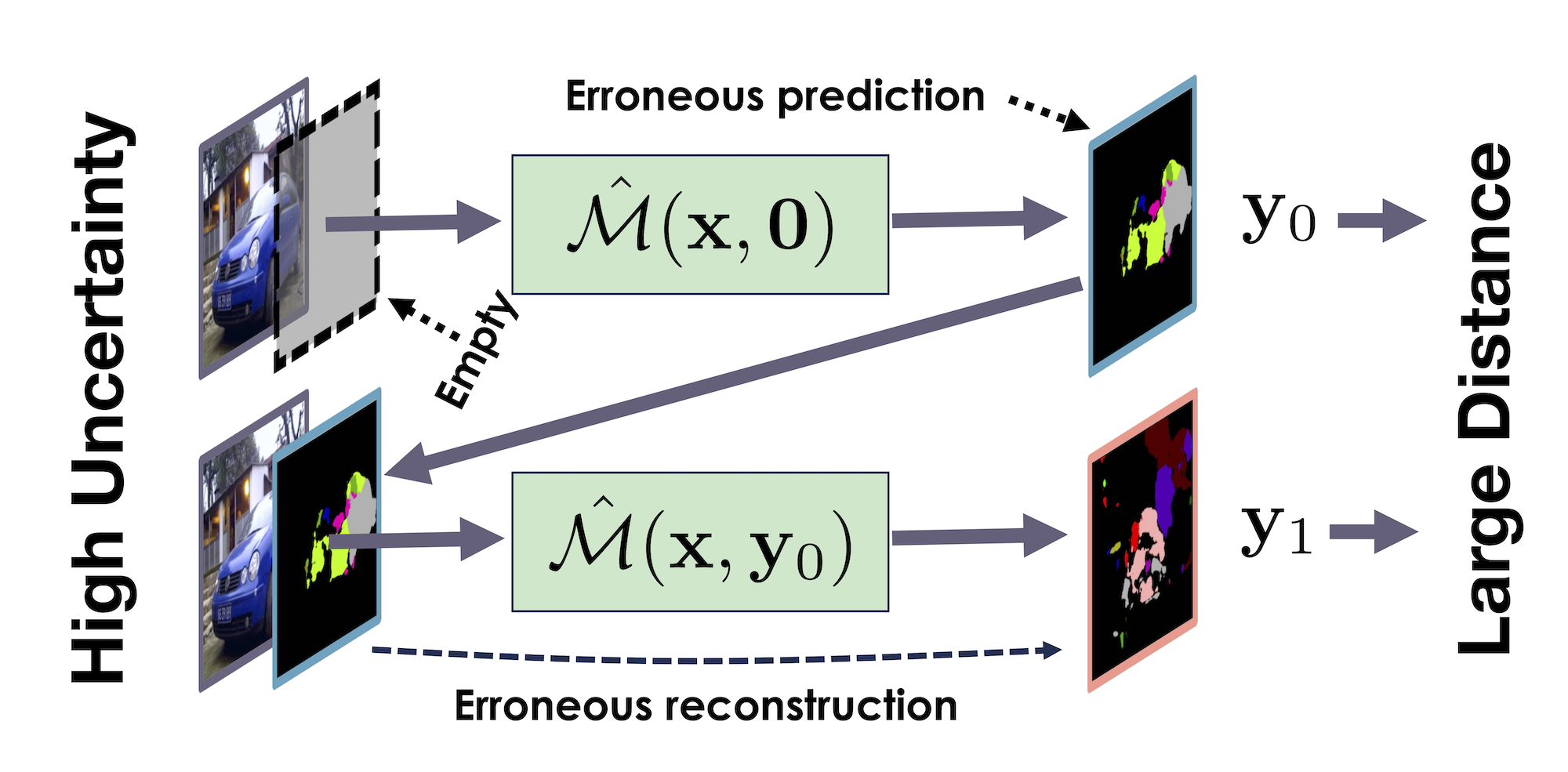
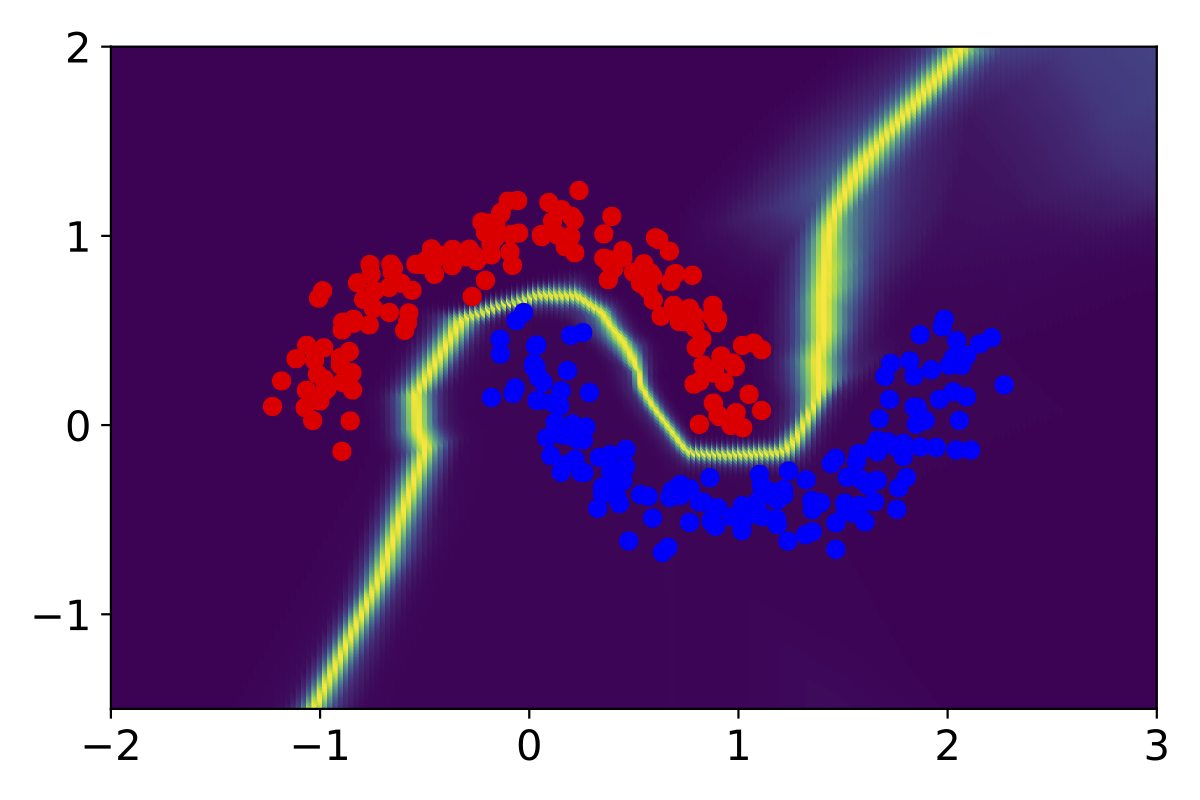
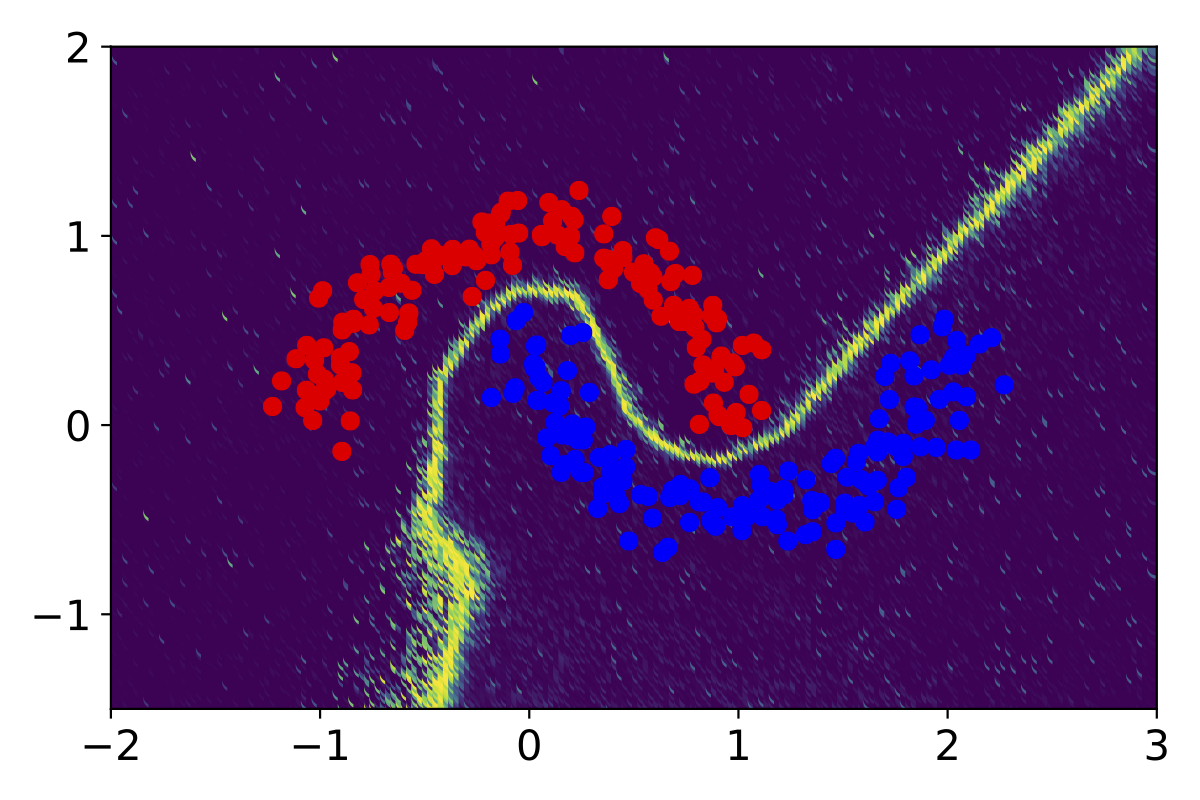
In this work, we introduce a sampling-free approach that is generic and easy to deploy, while producing reliable uncertainty estimates on par with state-of-the-art methods at a significantly lower computational cost. It is predicated on training the network to produce the same output with and without additional information about it. At inference time, when no prior information is given, we use the network's own prediction as the additional information. We then take the distance between the predictions with and without prior information as our uncertainty measure.
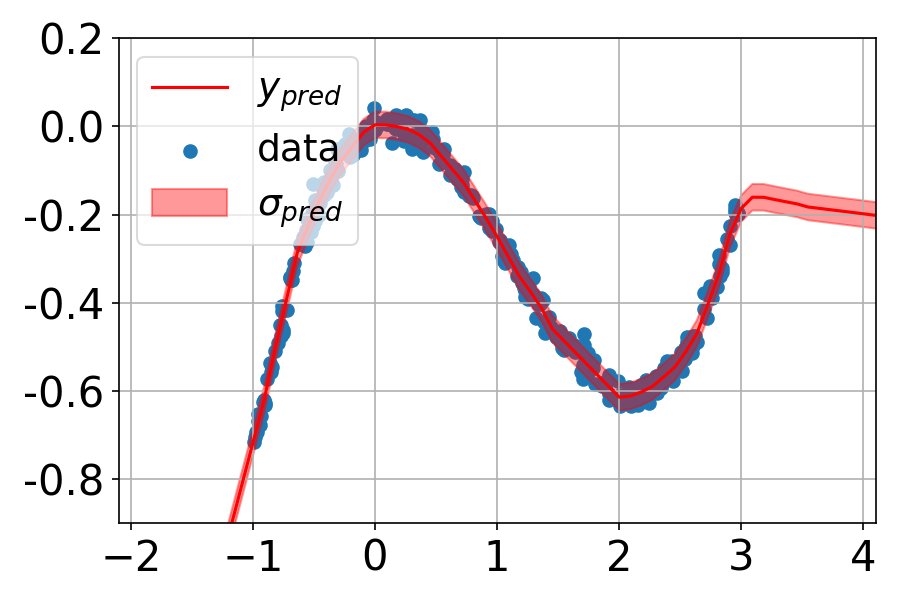
We demonstrate our approach on several classification and regression tasks. We show that it delivers results on par with those of Ensembles but at a much lower computational cost.
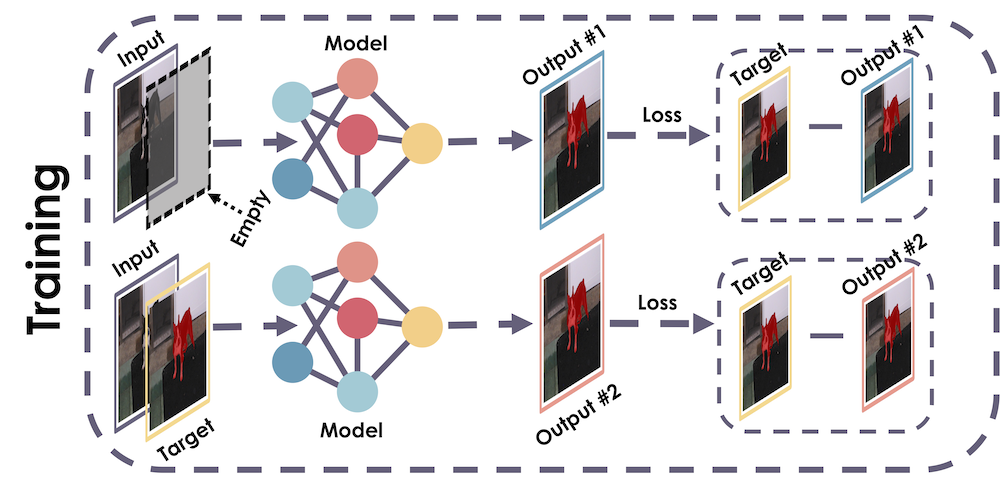
Zigzag's training scheme
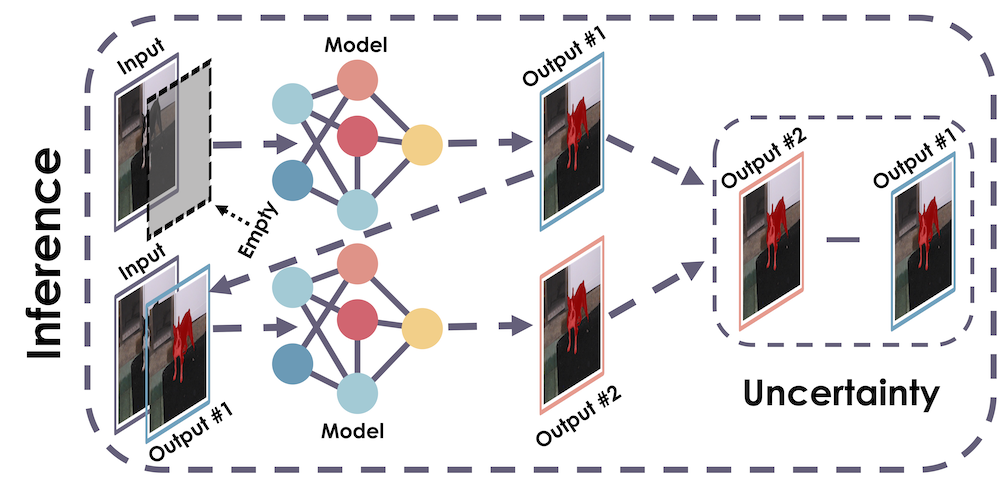
Zigzag's dual inference approach
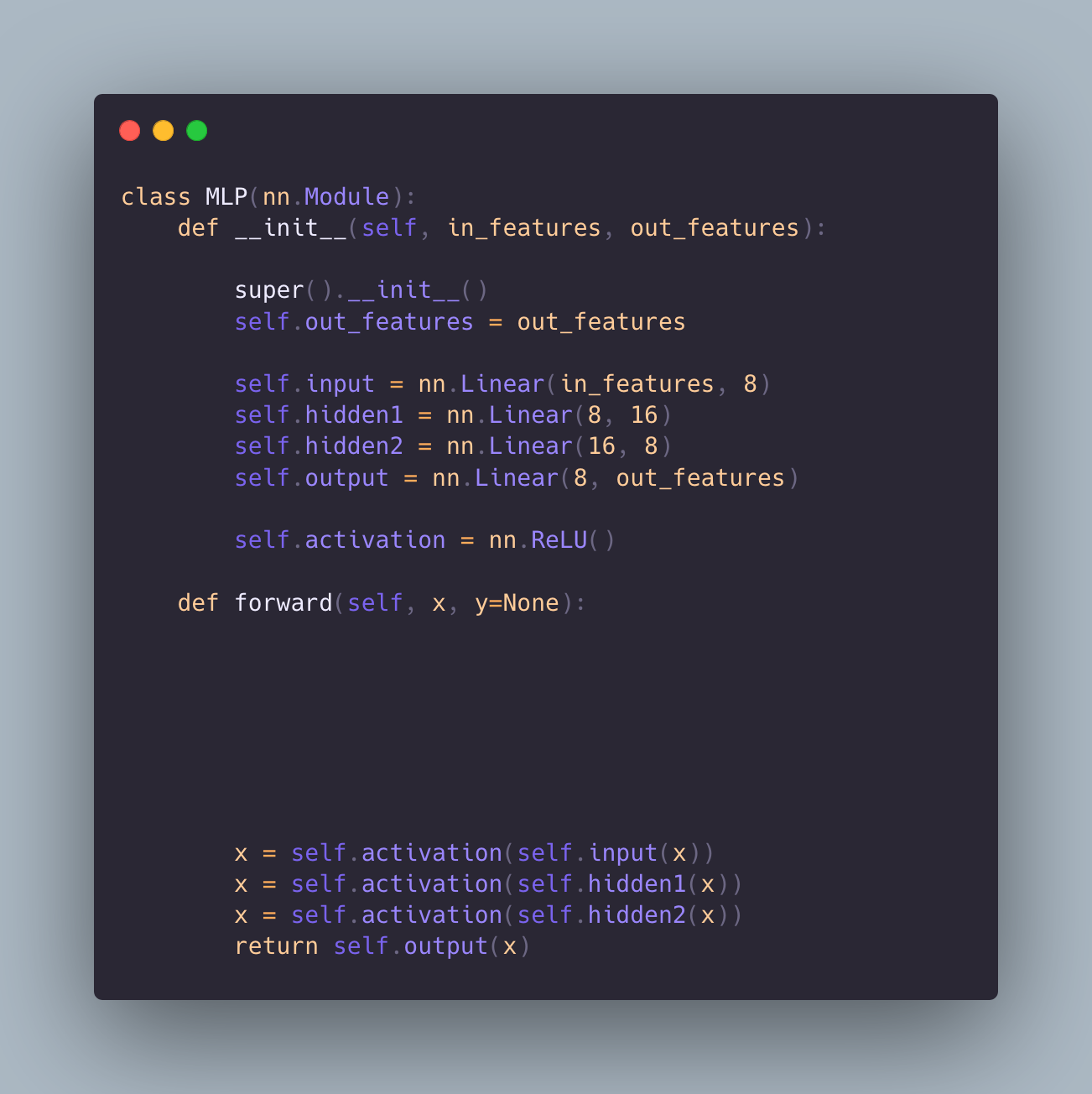
Original Model
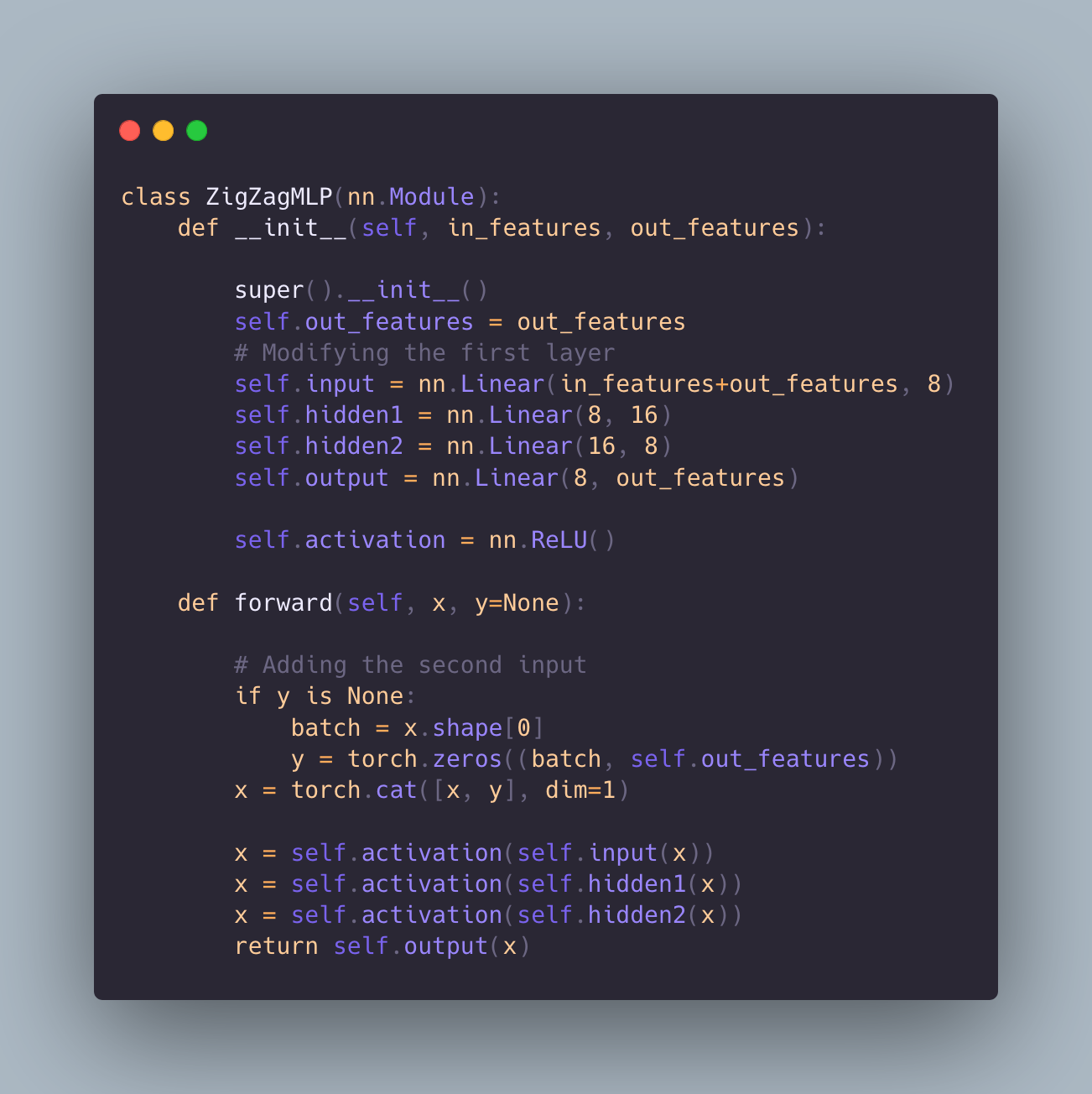
Modified Model
Single Model
MC-Dropout
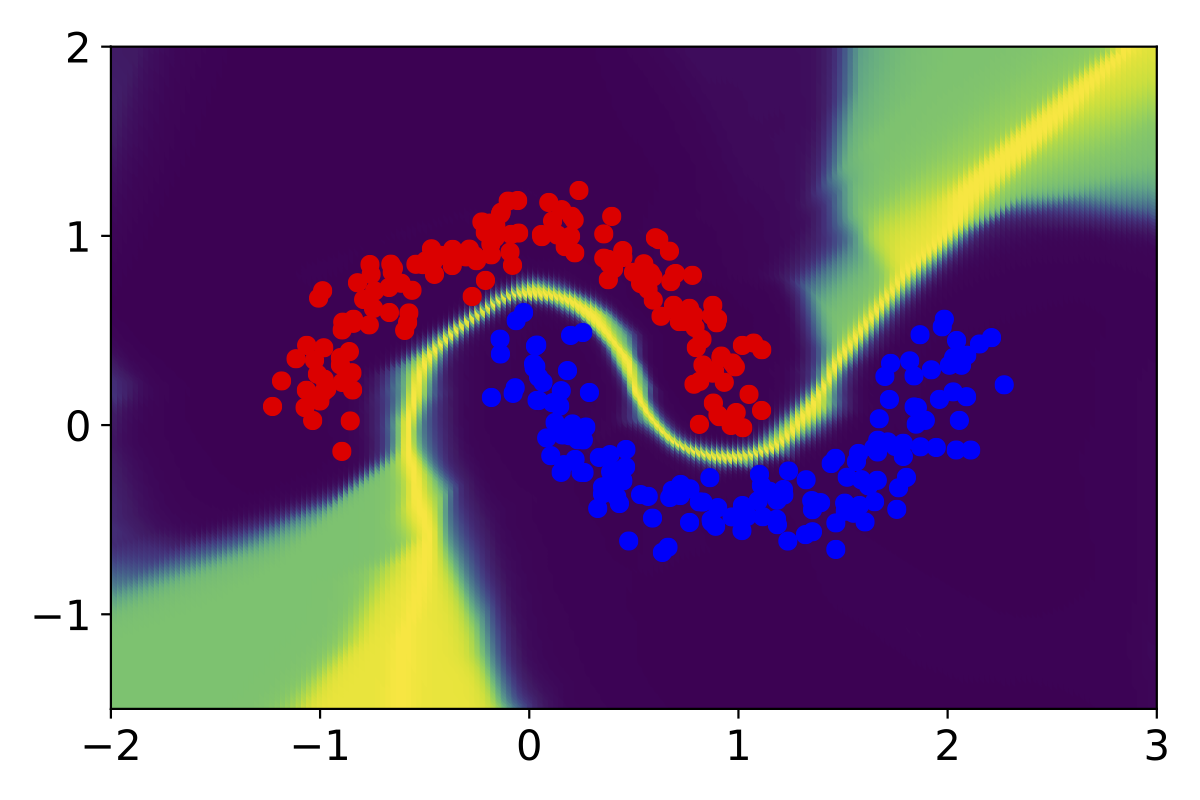
Deep Ensembles
ZigZag
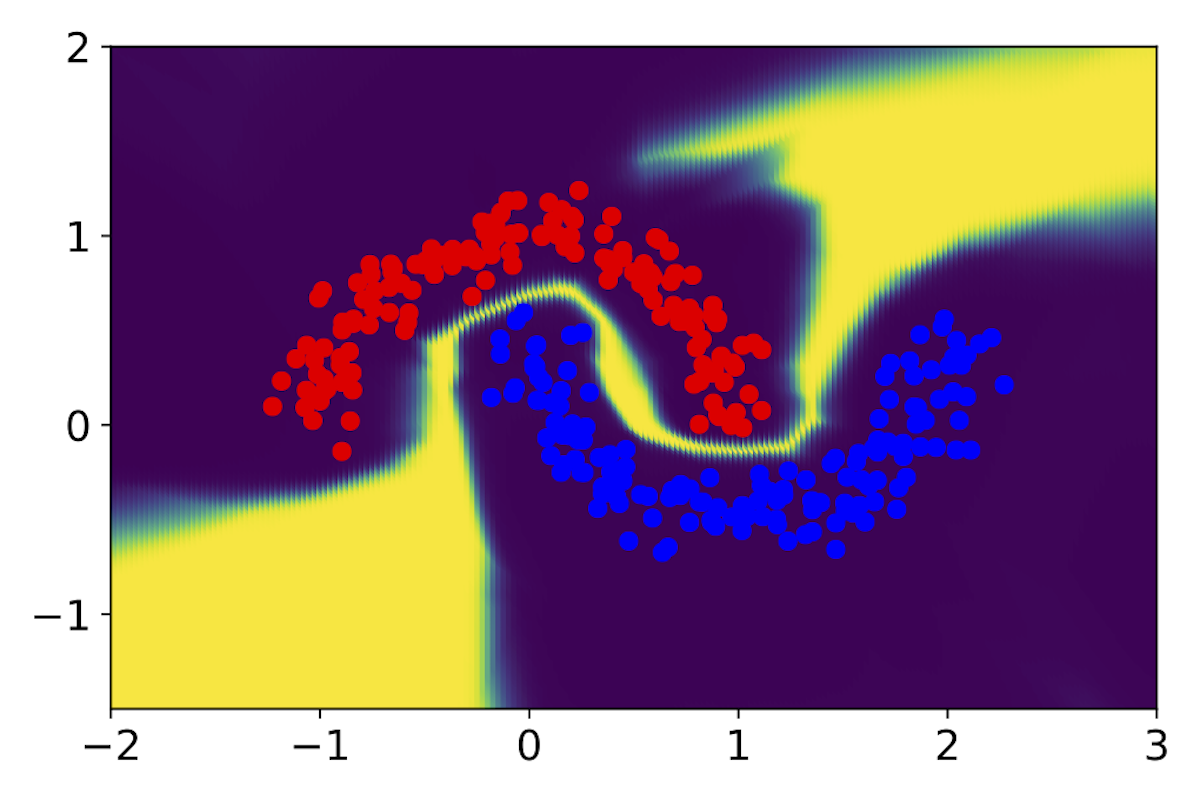
Single Model
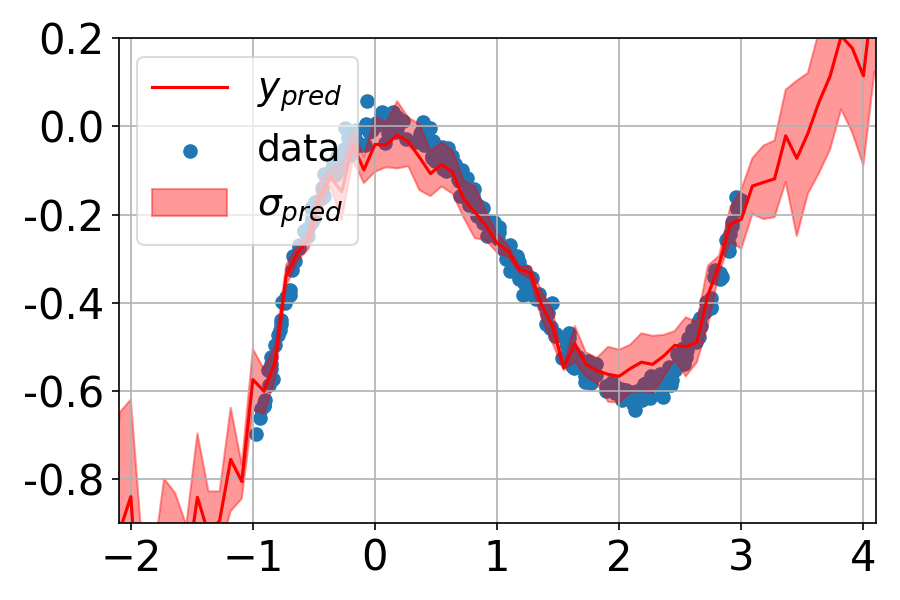
MC-Dropout
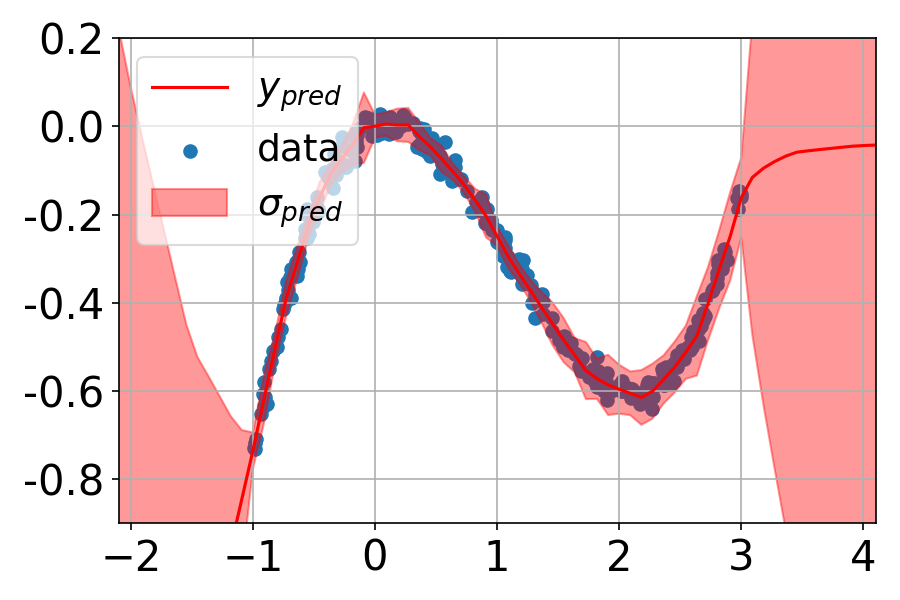
Deep Ensembles
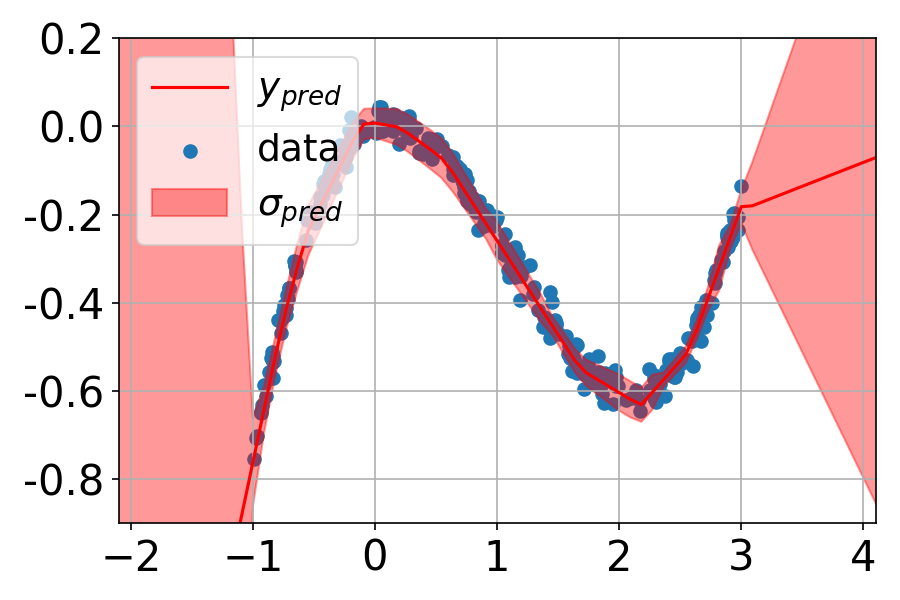
ZigZag
| [MC-Dropout] | [DeepE] | [BatchE] | [MaskE] | [Single] | [EDL] | [OC] | [SNGP] | [VarProb] | ZigZag | Dataset | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Accuracy | 0.981 | 0.990 | 0.989 | 0.989 | 0.980 | 0.975 | 0.980 | 0.984 | 0.986 | 0.982 | MNIST |
| rAULC | 0.932 | 0.958 | 0.941 | 0.929 | 0.712 | 0.955 | 0.851 | 0.813 | 0.731 | 0.961 | |
| Size | 1x | 5x | 1.2x | 1x | 1x | 1x | 1.3x | 1x | 1x | 1x | |
| Inf. Time | 5x | 5x | 5x | 5x | 1x | 1x | 1.4x | 1.7x | 1.2x | 2x | |
| Time | 1.3x | 5x | 1.4x | 1.3x | 1x | 1x | 1.1x | 1.1x | 1.x | 1x | |
| ROC-AUC | 0.953 | 0.984 | 0.965 | 0.963 | 0.773 | 0.947 | 0.934 | 0.951 | 0.812 | 0.982 | |
| PR-AUC | 0.962 | 0.979 | 0.965 | 0.966 | 0.844 | 0.923 | 0.923 | 0.942 | 0.861 | 0.981 | |
| Accuracy | 0.909 | 0.929 | 0.911 | 0.901 | 0.8901 | 0.912 | 0.892 | 0.905 | 0.895 | 0.928 | CIFAR |
| rAULC | 0.889 | 0.911 | 0.884 | 0.889 | 0.884 | 0.596 | 0.583 | 0.742 | 0.715 | 0.897 | |
| Size | 1x | 5x | 1.2x | 1x | 1x | 1x | 1x | 1x | 1x | 1x | |
| Inf. Time | 5x | 5x | 5x | 5x | 1x | 1x | 1.1x | 1.1x | 1.2x | 2x | |
| Time | 1.2x | 5x | 1.4x | 1.3x | 1x | 1x | 1.3x | 1x | 1.2x | 1.2x | |
| ROC-AUC | 0.854 | 0.915 | 0.877 | 0.900 | 0.825 | 0.864 | 0.851 | 0.900 | 0.831 | 0.901 | |
| PR-AUC | 0.918 | 0.949 | 0.919 | 0.931 | 0.875 | 0.903 | 0.821 | 0.891 | 0.861 | 0.933 |
@article{durasov2024zigzag,
title = {ZigZag: Universal Sampling-free Uncertainty Estimation Through Two-Step Inference},
author = {Nikita Durasov and Nik Dorndorf and Hieu Le and Pascal Fua},
journal = {Transactions on Machine Learning Research},
issn = {2835-8856},
year = {2024}
}